Il presente articolo è dedicato ad un argomento fondamentale di statistica, ovvero le distribuzioni continue.
Distribuzioni continue di una sola variabile
Definizione di variabile continua e densità di probabilità
Consideriamo una situazione in cui ad un determinato evento, cioè il risultato di una misura o di un esperimento, è associato un numero reale \(x\). Ipotizziamo che tale numero possa assumere un qualunque valore compreso tra due estremi \(a\) e \(b\), ossia \(a \leq x \leq b\). Poiché i numeri reali compresi tra \(a\) e \(b\) formano un insieme continuo, diremo che \(x\) è una variabile continua. Notiamo che non ha alcuna utilità chiedersi quale sia la probabilità che, a seguito di una misura, una variabile continua assuma un valore ben definito. Infatti, tale probabilità è sempre nulla. È invece interessante capire quale sia la probabilità che il valore misurato sia compreso tra \(x\) e \(x + \mathrm{d} x\), cioè in un intervallo infinitesimo di ampiezza \(\mathrm{d} x\). Ci aspettiamo che tale probabilità, che denotiamo con \( \mathrm{d} w(x) \), sia proporzionale all’ampiezza dell’intervallo. Possiamo formalizzare questa affermazione scrivendo
\(\mathrm{d} w(x) = P(x) \mathrm{d} x .\)
La funzione \(P(x)\) si dice densità di probabilità. Essa deve sempre assumere segno positivo, e deve soddisfare la condizione di normalizzazione
\(\int_a^b \mathrm{d} w(x) = \int_a^b P(x) \mathrm{d} x = 1 .\)
Valor medio e varianza
Consideriamo ora un’arbitraria funzione \(f(x)\) della nostra variabile continua \(x\). Una quantità utile a caratterizzare questa funzione è il suo valor medio, definito come:
\(\bar{f} = \int_a^b f(x) \mathrm{d} w(x) = \int_a^b f(x) P(x) \mathrm{d} x.\)
Il valor medio gode delle seguenti proprietà:
- se \(f(x)=\alpha\) è una funzione costante, allora \(\bar{\alpha}=\alpha\);
- il valor medio della somma di due funzioni è pari alla somma dei valori medi di ciascuna singola funzione: \(\overline{(f+g)} = \bar{f}+\bar{g}\);
- se \(\alpha\) è una costante, allora \(\overline{(\alpha f)} = \alpha\bar{f}\).
Ponendo \(f(x)=x\) nelle espressioni precedenti si ottiene il valor medio della distribuzione di probabilità:
\(\bar{x} = \int_a^b x P(x) \mathrm{d} x .\)
Questa quantità è una caratteristica intrinseca della distribuzione. Si potrebbe essere tentati di definire una seconda quantità caratteristica considerando il valor medio della funzione \(f(x)=x-\bar{x}\), che quantifica lo scarto di un valore misurato dal valor medio. Tuttavia, è immediato verificare che questa grandezza è sempre nulla, indipendentemente dalla distribuzione: \(\overline{(x-\bar{x})} = \bar{x} -\overline{(\bar{x})} = 0\). Ciò è legato al fatto che lo scarto può assumere valori sia positivi che negativi. D’altra parte, il valor medio di \(f(x) = (x – \bar{x})^2\), cioè del quadrato dello scarto di \(x\) da \(\bar{x}\), è generalmente diverso da zero. Esso definisce la varianza della distribuzione di probabilità,
\(\sigma^2 = \overline{(x-\bar{x})^2} = \overline{(x^2-2x\bar{x}+\bar{x}^2)} = \overline{x^2}-2\bar{x}^2+\bar{x}^2 = \overline{x^2}-\bar{x}^2 \geq 0 .\)
Pertanto, per caratterizzare una distribuzione si può usare la sua varianza o, equivalentemente, la sua deviazione standard
\(\sigma = \sqrt{\overline{(x-\bar{x})^2}} .\)
Distribuzioni continue di più variabili
Generalità
Tutti i concetti sopra esposti possono essere facilmente generalizzati al caso in cui una distribuzione di probabilità dipenda da \(n\) variabili continue \(x_1, x_2, \ldots, x_n\). Denoteremo con
\(\mathrm{d} w(x_1,x_2,\ldots,x_n) = P(x_1,x_2,\ldots,x_n) \mathrm{d} x_1 \mathrm{d} x_2 \cdots \mathrm{d} x_n\)
la probabilità che la prima variabile assuma valori compresi tra \(x_1\) e \(x_1 + \mathrm{d} x_1\), la seconda tra \(x_2\) e \(x_2 + \mathrm{d} x_2\), e così via. La condizione di normalizzazione assume la forma
\(\int_I \mathrm{d} w(x_1,x_2,\ldots,x_n) = \int_I P(x_1,x_2,\ldots,x_n) \mathrm{d} x_1 \mathrm{d} x_2 \cdots \mathrm{d} x_n = 1 .\)
Qui l’integrazione è estesa all’insieme \(I\) dei valori che le variabili \(x_1, x_2, \ldots, x_n\) possono assumere. Analogamente, se \(f(x_1,x_2,\ldots,x_n)\) è una qualunque funzione delle nostre \(n\) variabili continue, il suo valor medio è dato dalla formula
\(\begin{aligned} \bar{f} &{} = \int_I f(x_1,x_2,\ldots,x_n) \mathrm{d} w(x_1,x_2,\ldots,x_n) \\ &{} = \int_I f(x_1,x_2,\ldots,x_n) P(x_1,x_2,\ldots,x_n) \mathrm{d} x_1 \mathrm{d} x_2 \cdots \mathrm{d} x_n .\end{aligned}\)
Come caso particolare dell’espressione precedente, notiamo che il valor medio \(\bar{x}_i\) della \(i\)-esima variabile \(x_i\) si ottiene prendendo \(f(x_1,x_2,\ldots,x_n) = x_i\), mentre per avere la sua varianza \(\sigma_i^2\) bisogna scegliere \(f(x_1,x_2,\ldots,x_n) = (x_i – \bar{x}_i)^2\).
Il concetto di indipendenza statistica
Per semplicità, cominciamo considerando una distribuzione che dipenda solo da due variabili. Qui si nota immediatamente una novità: se le due variabili sono statisticamente indipendenti, la loro probabilità si calcola ragionando in maniera analoga a quando si hanno due eventi indipendenti. Formalmente, se la funzione di distribuzione è data da un’espressione del tipo
\(P(x_1,x_2) = P_1(x_1) P_2(x_2) ,\)
allora si ha
\(\begin{aligned} \mathrm{d} w(x_1,x_2) &{} = P(x_1,x_2) \mathrm{d} x_1 \mathrm{d} x_2 \\ &{}= P_1(x_1)P_2(x_2) \mathrm{d} x_1 \mathrm{d} x_2 \\ &{}= \left[P_1(x_1)\mathrm{d} x_1\right] \left[P_2(x_2) \mathrm{d} x_2\right] \\ &{}= \mathrm{d} w_1(x_1) \, \mathrm{d} w_2(x_2) . \end{aligned}\)
Si può quindi affermare che, se P si può rappresentare come un prodotto di due distribuzioni, ciascuna dipendente da una singola variabile, allora le due variabili sono indipendenti. Viceversa, se \(x_1\) e \(x_2\) sono distribuite in maniera indipendente, allora la loro funzione di distribuzione ammette la fattorizzazione appena vista. Una conseguenza interessante dell’indipendenza statistica di \(x_1\) e \(x_2\) è che, data una funzione del tipo \(f(x_1,x_2) = f_1(x_1) f_2(x_2)\), il suo valor medio ha anch’esso un’espressione fattorizzata,
\(\begin{aligned} \bar{f} &{}= \int_I f_1(x_1) f_2(x_2) \mathrm{d} w(x_1,x_2) \\ &{}= \int_I f_1(x_1) f_2(x_2) P_1(x_1) P_2(x_2) \mathrm{d} x_1 \mathrm{d} x_2 \\ &{}= \left[\int_{I_1} f_1(x_1) P_1(x_1) \mathrm{d} x_1\right] \left[\int_{I_2} f_2(x_2) P_2(x_2) \mathrm{d} x_2\right] \\ &{}= \bar{f}_1 \bar{f}_2 . \end{aligned}\)
Nell’ultima espressione abbiamo denotato con \(I_1\) e \(I_2\) gli insiemi dei valori che posso essere assunti rispettivamente da \(x_1\) e \(x_2\).
In presenza di tre o più variabili continue si possono avere situazioni più complicate. Ad esempio, prendiamo una distribuzione di tre variabili continue tale che \(P(x_1,x_2,x_3) = P_1(x_1) P_{23}(x_2,x_3)\). Si può allora dire che \(x_1\) è statisticamente indipendente da \(x_2\) ed \(x_3\), ma queste ultime non sono indipendenti tra loro. Se si prende una funzione del tipo \(f(x_1,x_2) = f_1(x_1) f_{23}(x_2,x_3)\), il suo valor medio sarà del tipo \(\bar{f} = \bar{f}_1 \bar{f}_{23}\). Possono dunque esserci casi in cui si hanno sottoinsiemi di variabili non indipendenti.
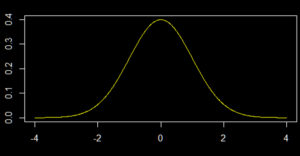
Una delle distribuzioni continue più note e che presenta un enorme numero di applicazioni è certamente la distribuzione normale o gaussiana, che presentiamo in questo articolo.