Quando abbiamo a che fare con algoritmi di classificazione è opportuno conoscere la nozione di matrice di confusione. Questo articolo è proprio dedicato a spiegare questo fondamentale concetto.
Come è fatta e come si legge una matrice di confusione?
Una matrice di confusione ha una forma tabellare. Partiamo dal caso più semplice, ovvero dal caso in cui abbiamo a che fare con due classi. Stiamo cercando di classificare, ovvero di mettere nella giusta “scatola” un’entità.
La matrice dunque dovrà contenere sia i dati attuali, cioè l’appartenenza di un’entità alla sua classe specifica, sia i dati predetti, ovvero il modo in cui l’algoritmo ha classificato quell’entità. Una confusion matrix a due classi ha generalmente questo aspetto:
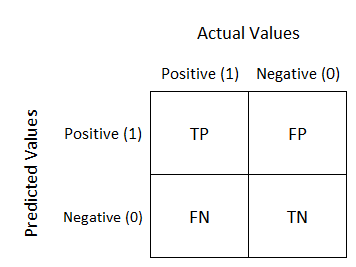
Possiamo subito notare che i valori predetti si trovano lungo le righe, mentre quelli attuali si trovano sulle colonne. Nel paragrafo successivo illustriamo le possibilità di classificazione.
Veri, falsi, positivi, negativi
Prima di inoltrarci ulteriormente nell’argomento è necessario chiarire bene cosa si intenda con le espressioni vero positivo, falso positivo, vero negativo, falso negativo. Le spieghiamo ed esemplifichiamo di seguito:
- vero positivo (true positive): è il caso di una classificazione corretta. Ad esempio quando si diagnostica una malattia ad un paziente che è realmente affetto da quella malattia;
- vero negativo (true negative): è il caso di un classificazione corretta. Ad esempio nella diagnosi per un paziente una certa malattia viene esclusa e realmente il paziente non soffre di quella malattia;
- falso positivo (false positive): è il caso di una classificazione non corretta. Ad esempio quando si diagnostica ad un paziente una certa malattia, ma il paziente non è realmente affetto da quella malattia. Il falso positivo viene definito come errore di tipo 1;
- falso negativo (false negative): è il caso di una classificazione non corretta. Ad esempio quando non si diagnostica ad un paziente una certa malattia, ma il paziente è realmente affetto da quella malattia. Il falso negativo viene definito come errore di tipo 2.

Un esempio di matrice di confusione
Vogliamo ora creare noi stessi dei dati, in modo tale da comprendere meglio il tema dell’articolo. Supponiamo quindi di avere a disposizione la seguente matrice di confusione:
Vediamo di leggerla insieme. Lungo le righe troviamo i dati attuali: i veri negativi (TN) sono i casi di diagnosi corrette, secondo le quali il paziente non ha la malattia, mentre i falsi positivi (FP), sono casi di diagnosi scorrette che attribuiscono la malattia ad un soggetto sano. Lungo la prima riga troviamo dunque il totale degli individui sani.
Lo stesso ragionamento si ripete per la seconda riga: qui troviamo il totale degli individui malati, somma dei casi falsi negativi (FN) e veri positivi (TP).
La terza riga invece riguarda il totale dei classificati (non dati attuali), divisi tra individui malati e sani. Come si può notare dai dati, il nostro ipotetico classificatore non è certo privo difetti.
A questo punto dobbiamo stimare la bontà della nostro classificatore e pertanto dobbiamo introdurre le metriche che possiamo ricavare dalla matrice di confusione. Le trattiamo nel seguente paragrafo.
Le metriche di una matrice di confusione
Tasso di errore (EER)
Il tasso di errore è la somma degli errori di classificazione diviso per il numero totale dei casi. L’EER è dato dalla seguente formula:
\(ERR = \frac{FP+FN}{TN+FP+TP+FN} \)
Si noti che il tasso di errore è necessariamente compreso tra 0 e 1. 0 è il migliore caso possibile, 1 il peggiore.
Nel nostro esempio quindi:
\(ERR = \frac{130+110}{400} = 0,6 \)
Accuratezza (Accuracy)
L’accuratezza è la somma delle classificazioni corrette diviso per il numero totale dei casi. L’accuratezza è data dalla seguente formula:
\(ACC = \frac{TP+TN}{TN+FP+TP+FN} \)
Si noti che l’accuratezza è necessariamente compreso tra 0 e 1. 1 è il migliore caso possibile, 0 il peggiore.
Nel nostro esempio quindi:
\(ACC = \frac{40+120}{400} = 0,4\)
Notiamo anche che il tasso d’errore e l’accuratezza sono definibili l’uno rispetto all’altro, secondo le seguenti formule:
\(ERR = 1 – ACC\)
\(ACC = 1 – ERR\)
Ciò significa che avendo l’una delle due metriche possiamo calcolare facilmente anche l’altra.
Sensibilità (sensitivity)
La sensibilità è la misura di quanto un classificatore “sia buono” nel trovare gli attuali casi positivi. Essa è data dalla seguente formula:
\(Sn = \frac{TP}{TP+FN}\)
Nel nostro esempio abbiamo dunque che:
\(Sn = \frac{40}{40+110} = 0,26\)
Specificità (specificity)
La specificità è la misura di quanto il nostro classificatore si sia dimostrato abile nel classificare i casi negativi. Essa è data dalla seguente formula:
\(SP = \frac{TN}{TN+FN}\)
Nel nostro esempio abbiamo dunque che:
\(SP = \frac{120}{120+130} = 0,48\)
Precisione (precision)
La precisione quantifica la bontà del classificatore nelle attribuzioni positive. La formula è data dalla seguente formula:
\(PR = \frac{TP}{TP+FP}\)
Nel nostro esempio abbiamo dunque che:
\(PR = \frac{40}{40+130} = 0,23\)
Rateo dei falsi positivi (false positive rate)
Il rateo dei falsi positivi è il rapporto tra il numero di previsioni positive errate diviso il totale dei casi negativi, secondo la seguente formula:
\(FPR= \frac{FP}{TN+FP} \)
Nel nostro esempio abbiamo dunque che:
\(Pr = \frac{130}{120+130} = 0,52\)
Si noti che il rateo dei falsi positivi e la specificità sono definibili reciprocamente secondo le seguenti formule:
\(SP = 1 – FPR\)
\(FPR = 1 – SP\)
Tabella riassuntiva delle metriche della matrice di confusione
La valutazione di un modello
È normale a questo punto essere disorientati. Abbiamo spiegato cosa sia una matrice di confusione e abbiamo introdotte le relative metriche che da essa possiamo ottenere. Non dimentichiamo, tuttavia, che queste metriche servono a valutare i risultati di un modello di classificazione.
La valutazione di un modello di classificazione si lega, infatti, sempre ad un contesto. Rimanendo in un contesto medico, potremmo trovarci davanti ad un caso simile al seguente. Immaginiamo che il nostro modello ecceda nel diagnosticare una malattia: classifica correttamente tutti i casi in cui la malattia affligge effettivamente un paziente, ma classifica anche come malati alcuni pazienti che di fatto non lo sono.
In un caso simile, tutto dipende dalla malattia in questione e dalle conseguenze della terapia o della sua assenza. Se la malattia è grave e contagiosa, preferiremmo un modello che diagnostica sempre la malattia, anche se in qualche caso la diagnostica anche per pazienti non malati. Siamo interessati al fatto che la malattia non si propaghi, quella è la nostra priorità, quindi il nostro algoritmo di classificazione, fin troppo zelante, potrebbe essere accettabile. Preferiremmo quindi un modello con alta sensibilità.
Un altro caso può riguardare una malattia che ha poche possibilità di contagio e che è poco grave. Tuttavia, la terapia, se fornita a pazienti che in realtà sono sani, può produrre tremendi effetti collaterali. In quel caso preferiremmo certamente un classificatore che individua i pazienti sani con maggiore precisione rispetto a quelli malati. Preferiremmo quindi un modello con alta specificità.
Si noti che, come abbiamo detto, queste considerazioni riguardano il contesto e lo scopo del classificatore. Ne segue che il classificatore perfetto è in realtà un concetto ideale: ciò che conta è l’efficacia di esso rispetto allo scopo nel contesto in cui ci troviamo. Generalmente in questi casi il data scientist modifica il modello in base alle esigenze, cambiando determinati parametri. Adattare un modello predittivo per ottenere risultati migliori rispetto un determinato contesto è un’operazione nota come tuning.