Quando parliamo di Big Data ci troviamo sempre ad avere a che fare con un po’ di confusione. Come ha scritto Dan Ariely:
Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.
I Big Data sono come il sesso tra adolescenti: tutti ne parlano, nessuno sa davvero come farlo, tutti pensano che tutti gli altri lo facciano, quindi tutti sostengono di farlo.
Proprio per evitare questa confusione, in questo articolo ci proponiamo di fornire quella che è la definizione che oramai si è affermata.
Big Data: un’espressione vaga
L’espressione Big Data porta con sé una certa vaghezza semantica e certi interrogativi. Innanzitutto possiamo chiederci da quale soglia dimensionale è lecito parlare di Big Data, ovvero quanto devono essere grandi i nostri dati
per utilizzare la suddetta espressione. Prendiamo quindi in considerazione lo sviluppo delle tecnologie atte a manipolare i dati.
Aumento delle memorie
Rispondere a questa domanda con una cifra puntuale potrebbe rivelarsi la strategia errata. L’avanzare della tecnologia, sia nei rispetti della capacità di memorizzazione, sia nei rispetti della velocità di calcolo, sia in quelli della
velocità di connessione, rende molto arduo, se non impossibile, fornire una soglia che si mantenga adeguata anche solo nel breve periodo. Tuttavia è possibile ottenere qualche indicazione, anche storica, su come le tecnologie hanno progredito, anche solo dal lato consumer.
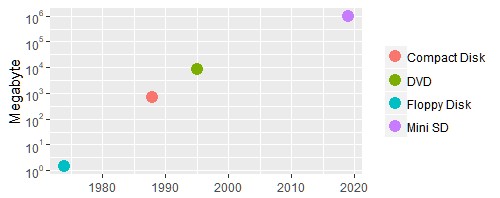
Il grafico riportato sopra mostra semplicemente l’incremento negli ultimi quaranta anni dei volumi di memoria per tecnologie di utilizzo quotidiano. Si può notare un aumento di ben sei grandezze d’ordine.
Aumento della velocità di calcolo dei processori
Possiamo poi considerare il seguente grafico .
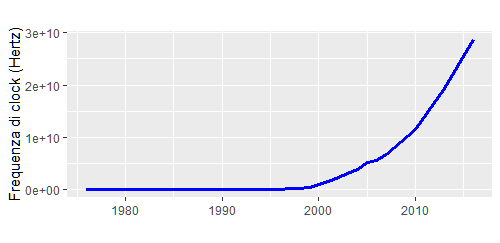
Esso illustra la velocità di clock dei microprocessori, ovvero la frequenza con cui una central processing unit (CPU ) può svolgere un certo numero di operazioni di calcolo basilari nell’unità di tempo. Più chiaramente, questo `e un modo di quantificare la velocità con cui i computer manipolano i dati.
Diffusione della banda larga
In ultimo, possiamo considerare con il grafico successivo la penetrazione della banda larga (broadband), un tipo di connessione la quale garantisce la trasmissione di dati sulla rete ad almeno 2 Mbit/s.
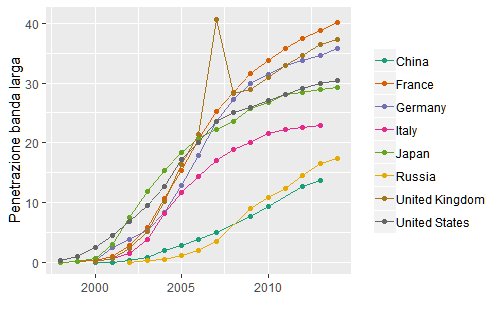
Questi grafici, nel loro insieme, testimoniano come negli ultimi venti anni le capacità di produrre, memorizzare, manipolare, e trasmettere i dati abbiano conosciuto un incremento esponenziale, iniziando un trend di cui difficilmente si vede l’apice.
Di conseguenza, quando parliamo di Big Data, consci di questa crescita nelle capacità informatiche, dovremmo intendere più un certo stato dell’arte che delle metriche specifiche. Quello che oggi è classificabile come una grande mole di dati, plausibilmente non lo sarà nel giro di qualche anno.
Una definizione migliore di Big Data: 4V+1
Stabilita l’impossibilità di definire il termine Big mediante un valore numerico, possiamo adottare un approccio certamente migliore e oramai affermatosi.
Questo approccio consente di parlare di Big Data quando i dati considerati presentano le seguenti quattro caratteristiche:
- Volume (Volume): abbiamo già affermato che non è possibile dare una soglia numerica per poter parlare legittimamente di Big Data. Se volessimo tuttavia continuare su questa strada potremmo definire big un quantitativo di dati non gestibile da un singolo calcolatore.
- Varietà (Variety): non è sufficiente avere molti dati, ma i dati tra loro devono anche essere eterogenei. I dati si presentano in molte vesti, dai dati testuali ai dati multimediali, dai tweet alle interazioni sui social.
- Veridicità (Veracity): i dati di cui disponiamo devono essere attendibili e questa caratteristica deve essere intesa come la conditio sine qua non poter produrre analisi di qualità.
- Velocità (Velocity): ovvero un alto valore di dati prodotti per unità di tempo. Anche qui il valore numerico è relativo. Tuttavia, nel tempo dell’ Internet delle Cose in cui viviamo i dati vengono prodotti ad una velocità impressionante.
Un’infografica di IBM ci aiuterà ad avere un quadro più immediato.

Valore
Come accennavamo a queste 4 V se ne aggiunge una quinta, il valore. La massiva e continua produzione di dati porta con sé un valore difficilmente quantificabile, ma certamente enorme. Il diffondersi di tecniche di analisi
basate sull’apprendimento automatico (machine learning) e sull’intelligenza artificiale (si pensi ad esempio alle reti neurali) ha permesso tutta una serie di progressi in diversi campi: mediante questi algoritmi si è in grado di diagnosticare malattie, scoprire nuovi corpi celesti, profilare le caratteristiche psicologiche degli individui, predire la solvibilità o meno di situazioni debitorie, personalizzare profili assicurativi, utilizzare algoritmi predittivi per il contrasto al crimine e molto altro ancora.
Quando parliamo di Big Data quindi dobbiamo tenere presente il significato e l’importanza di queste 5 V, proprio per non fare la figura degli adolescenti di cui parlava Dan Ariely.
Questo articolo è tratto dal mio lavoro di tesi per il Corso di Alta Formazione in Data Protection and Privacy Officer dell’Università di Bologna. La tesi è leggibile full-text su ResearchGate.